Репликация Master-Slave используется для обеспечения отказоустойчивости доступа к базам. Также позволяет распределить нагрузку на базы данных между несколькими серверами.
Сама по себе репликация выгляди как подход к масштабированию баз. Данные с одного сервера базы данных постоянно копируются (зеркалируются) на другие подобные серверы. Для прикладных программ это дает возможность использовать не один сервер для обработки всех запросов, даже без балансировщкиа. Таким образом появляется возможность распределения нагрузки.
Виды взаимодействия серверов: Ведущий и Ведомый и/или Ведущий и Ведущий
Ведущий и Ведомый
В этом варианте выделяется один основной сервер базы данных, который называется Ведущим. Он обрабатывет любые запросы – INSERT,UPDATE,DELETE. Ведомый сервер следит и копирует все изменения с Ведущего. Прикладные программы часто используют Ведомый сервер для запросов чтения данных – SELECT. Таким образом один отвечает за изменения данных, а второй за чтение. Прикладные приложения могут использовать явные паралельные соединения с серверами — одно для Ведущего, другое — для Ведомого
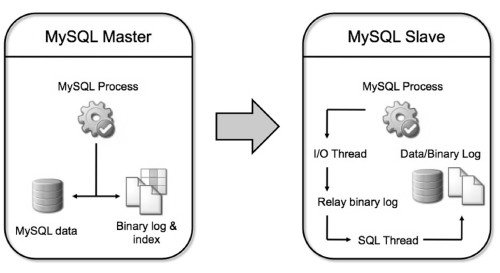
Часто используется более одного Ведомого сервера. Преимущество этого типа – только в случае высоких нагрузок чтения через балансировщик. Обычно непосредственно используют не более 10 Ведомых серверов на одного Ведущего. Но по факту все зависит от вычислительных возможностей сервера и типа сетевой связи. Прикладные программы могут самостоятельно выбирать алгоритм работы с серверами.
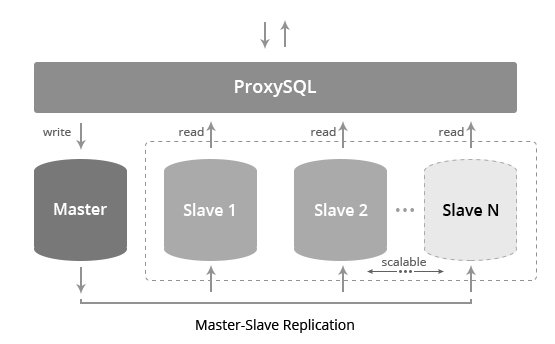
Задержки копирования
Асинхронность означает, что данные на могут появится на Ведомых серверах с задержками. Поэтому, в последовательных логических операциях функционального типа программирования необходимо использовать чтение с Ведущих, чтобы получать актуальные данные.
Резервирование и применяемость
Чаще всего этот тип используют не для масштабирования нагрузки, а для резервирования. В этом случае, Ведущий обрабатывает все запросы от приложения. Ведомый работает в пассивном режиме. Но в случае выхода из строя Ведущего, все операции можно быстро перевести на Ведомого.
Ведущий и Ведущий
В этом режиме, любой из серверов может использоваться как для чтения так и для записи. При использовании такого типа репликации достаточно выбирать случайное соединение из доступных Ведущих. В случае выхода из строя, серьезность сбоев делают этот вариант непривлекательным. Выход из строя одного из серверов практически всегда приводит к потере каких-то данных. Последующее восстановление также сильно затрудняется необходимостью ручного анализа данных, которые успели либо не успели скопироваться. Используйте такую репликацию только в крайнем случае. Вместо этого лучше пользоваться ручную репликацию, а еще лучше переходит на кластерный режим.
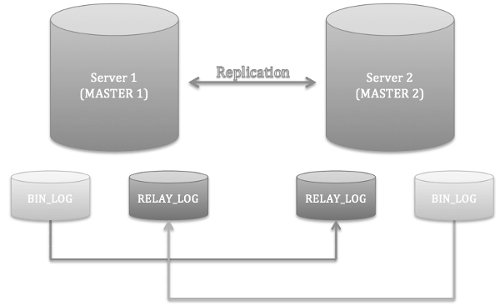
Асинхронность репликации
В MySQL репликация работает в асинхронном режиме. Это значит, что приложение не знает, как быстро данные появятся на Ведомом. Задержка в репликации (replication lag) может быть как очень маленькой, так и очень большой. Обычно рост задержки говорит о том, что сервера не справляются с текущей нагрузкой и их необходимо масштабировать дальше, например техниками горизонтального и вертикального шардинга.
Синхронный режим
Синхронный режим репликации позволит гарантировать копирование данных на Ведомого. Это упростит работу в приложении, т.к. все операции чтения можно будет всегда отправлять на него. Однако это может значительно уменьшить скорость работы MySQL. Синхронный режим не следует использовать в Web приложениях.
“Ручная” репликация
Следует помнить, что репликация — это не технология, а методика. Встроенные механизмы репликации могут принести ненужные усложнения либо не иметь какой-то нужной функции. Некоторые технологии вообще не имеют встроенной репликации. В таких случаях, следует использовать самостоятельную реализацию репликации. В самом простом случае, приложение будет дублировать все запросы сразу на несколько серверов базы данных. При записи данных, все запросы будут отправляться на несколько серверов. Зато операции чтения можно будет отправлять на любой сервер. Нагрузка при этом будет распределяться по всем доступным серверам.
Самое важное
Репликация используется в большей мере для резервирования баз данных и в меньшей для масштабирования. Ведущий-Ведомый репликация удобна для распределения запросов чтения по нескольким серверам. Подход ручной репликации позволит использовать преимущества репликации для технологий, которые ее не поддерживают. Зачастую репликация используется вместе с шардингом при решении вопросов масштабирования.
справочно – https://ruhighload.com/Репликация+данных